Homework 5: Deep Learning
Due date: Monday, May 1, 2023 at 11:55pm
Turn in a PDF submission. You may include photos of handwritten solutions within your PDF, but make sure it is legible. Points will be taken off for illegible solutions. Full credit on non-coding problems will only be assigned if your work is shown.
Question 1: Practice Final Exam Questions (3 points)
Answer each of the following multiple choice questions. Provide an explanation (at least 1 sentence) of your answer. Note that the explanation is not required for the final exam but is required for this homework. While these questions are focused on the Deep Learning portion of this class, the final exam will have questions covering all concepts from this semester (though much more questions on post-midterm material).
i. Which of the following activation functions, when applied to the nodes in the hidden layers of a multilayer perceptron, is not useful for a deep learning model? (0.25 points)
A. \(\frac{e^x - e^{-x}}{e^x + e^{-x}}\)
B. \(-min(4, x)\)
C. \(-0.4x + 0.2\)
D. \(max(0.1x, x)\)
ii. True or False: It is always better to train a neural network for as many epochs as possible. (0.25 points)
A. True
B. False
iii. Which of the following is NOT a reason why CNNs are preferred over MLPs for image processing? (0.25 points)
A. In convolutional layers, the parameters (i.e., kernels) of the convolutional layers are invariant to where the features appear in the image. This is not the case in dense layers.
B. The extracted features can be visualized by inspecting the activation maps.
C. Only CNNs can learn non-linear features for complex images.
D. All of the above are reasons why CNNs are preferred.
iv. Let’s say you have a MLP network which is trained on 5-dimensional input data. The network has 3 hidden layers, with 50, 30, and 20 nodes respectively. The network is trained to predict a 10-way classification task using softmax activation. If we ignore bias terms, how many weights does this neural network have? (0.25 points)
A. 2,550
B. 1,500,000
C. 115
D. 30,000
v. Suppose we have a 1000x1000x3 dimension input image (width x height x channel). We apply a convolutional layer with 50 5x5 kernels. What is the dimension of the resulting tensor (width x height x channel) if we have stride=1 and no padding? (0.25 points)
A. 995x995x3
B. 996x996x3
C. 995x995x50
D. 996x996x50
vi. Suppose you train a neural network. After a few epochs, you notice that the training F1 score is much higher than the validation F1 score. Which of the following is a potential solution? (0.25 points)
A. Increase the probability of Dropout.
B. Increase the regularization rate (hyperparameter).
C. Train a new network with fewer layers and fewer nodes per layer.
D. All of the above are possible solutions.
vii. Which of the following is NOT a benefit of Faster R-CNN over plain R-CNN for object detection? (0.25 points)
A. Faster computation time due to use of a single CNN to process regions rather than 1 CNN per region.
B. The compression of the network layers through network pruning.
C. A region proposal network allows for the learning of the optimal regions for the domain at hand.
D. All of the above are benefits of Faster R-CNN.
viii. True or False: Due to limitations in loss function design, it is impossible to design a system of neural networks (such as a GAN) which consists of more than 2 interacting neural networks. (0.25 points)
A. True
B. False
ix. Which of the following is NOT a benefit of Transformers over LSTMs for NLP? (0.25 points)
A. Sentences are processed as a whole rather than word-by-word, thus solving the vanishing gradients issue in a more optimal manner than the memory gates of an LSTM, as there is much less room for information loss.
B. Multi-head attention and positional embeddings explicitly provide information about the relationships between words.
C. Training and prediction can occur using parallel computing using Transformers, unlike any type of RNN which requires knowing information about the previous time steps to process the current time step.
D. All of the above are benefits of Transformers over LSTMs.
x. Which of the following methods is NOT used to reduce overfitting in a neural network? (0.25 points)
A. Data augmentation
B. Dropout regularization
C. Applying momentum to the gradient descent process
D. All of the above
xi. In gradient descent, does increasing the learning rate promote Exploration or Exploitation? (0.25 points)
A. Exploration
B. Exploitation
C. Learning rate does not affect this tradeoff
xii. What is the effect of setting the discount factor hyperparameter to 0 in Q-Learning? (0.25 points)
A. The agent will only learn actions that produce immediate reward.
B. The agent will evaluate each of its actions based on the sum total of all of its future rewards.
C. Setting the discount factor to 0 will not affect how the agent learns.
Question 2: Neural Network Output (1 point)
What is the output probability prediction of the following neural network given the input vector shown? Show your work.
Both hidden layers have ReLU activation applied to every node. The output layer uses sigmoid activation (for binary classification).
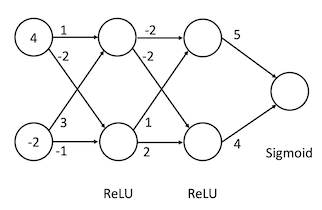
Question 3: Convolutional Neural Network Output (3 points)
What is the output probability prediction of the following very tiny convolutional neural network? This network was trained to classify whether the input 3x3 black and white image is depicting the letter “L” or not. Stride is 1 and padding is 0 for all layers. Show your work.
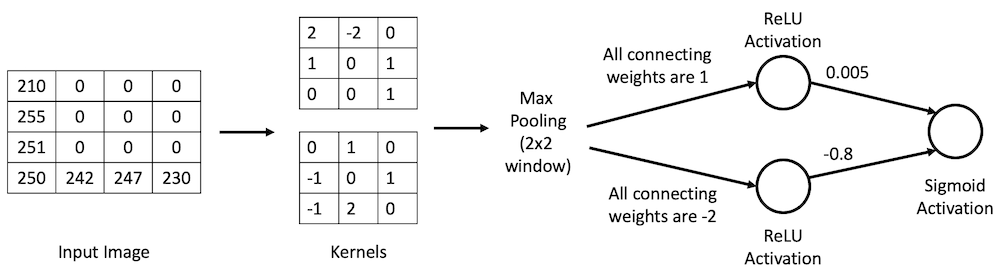
Question 4: TensorFlow / Keras Implementation (3 points)
The Olivetti faces dataset contains 10 images each of 40 different subjects. In this problem, you will build and train a neural network to predict the ID of the person based on an image of their face.
You will implement your neural network in TensorFlow/Keras. Make a copy of this Colab notebook and implement the get_neural_network() function. The function requirements are as follows:
- Input:
X_trainandy_train - Output: Trained TensorFlow neural network.
You will receive full credit for this question if your model achieves at least 85% F1-score on the test set in the notebook. No writeup required.
Rules:
- Your model and weights must be loadable into the free version of Google Colab.
- To ensure fairness and equity with computing access, you cannot train your model outside of Google Colab.
- You can change anything about this function - model architecture, number of epochs to train, loss function, learning rate, whether you start from randomly initialized model weights or very specific pre-trained weights, etc.
- You may only use the training set to train your model.
- We will be looking out for cheating (e.g., training on the test set and uploading that .h5 model, which would happen if your performance is abnormally high but your code doesn’t support that level of performance).
Create a copy of this Colab notebook. While you should understand the entire notebook, your task is to fill in the get_neural_network() function only.
We will load your saved .h5 file into an autograding notebook which you have access to during your assignment. You can therefore upload your model to ensure that it was created properly.
Extra credit will be provided as follows: 1 point for test F1-score above 88%, and additional point for every 3% increase in F1 score beyond that for a maximum of 5 extra credit points.
Submission instructions
Submit a PDF on Laulima. Make sure that your Colab notebook is publicly accessible. All of your code must be included in your submitted PDF.
You should also submit a .h5 file containing your TensorFlow model and weights. We will use this model for grading. Attach this file to your Laulima submission. To create this file, change your name in the student_name variable of the final code cell of the notebook and run the code cell to save the file. This will work best in Google Chrome.